Peeve: “The app owners bombard me with tickets and make me sit through endless calls for just one minor disable/enable operation.”
In our last blog, we spoke about the hurdles that network engineers face in deploying applications and how AppViewX helps them get around those hurdles. But as we all know, the story doesn’t quite end there.
“Now that the application is in production, we can all sit back and relax,” said no application owner ever. Developing and deploying applications is just the tip of the iceberg; the real deal lies in their maintenance- performance monitoring, bug fixes, feature updates, and version upgrades. The time, effort, and money that go into these maintenance activities usually override the development and deployment costs. That’s because while app development and deployment are one-shot jobs, maintenance is perpetual, lasting the app’s lifetime. If a typical enterprise-level app costs $100,000 to develop, it may take up to $30,000 to maintain every year.
Application maintenance doesn’t just end at the application level. Every change that’s done on an application invariably affects the underlying application service infrastructure comprising of load balancers, firewalls, proxy servers, etc. These devices, despite being closer to the application layer than the network layer, are largely considered “network devices” and their maintenance falls on the network engineer.
In keeping with the agile way of doing things, DevOps is driving faster and faster CI/CD cycles with the aim of making the latest apps available to end-users as quickly as possible. While the code itself might take only a few hours to build, the steps involved in pushing the code to the application are many and tricky –
- Disable application from the production environment of the primary server pool/DC
- Enable application in the standby pool/DC
- Enable application in the test/staging environment in the primary pool/DC
- Validate application for code correctness and behaviour
- Disable application from the test environment in the primary pool/DC
- Enable application back in the production environment of the primary server pool/DC
- Repeat the above steps for the standby pool/DC
In the above steps, except for the validation part, all the other steps require changes to be done in the network-layer devices. Redirecting traffic needs reconfiguration of load balancers and firewalls, while application enable/disable involves accessing the servers on which they’re hosted. Since application owners seldom dip their hands into the network pie, it becomes the network engineer’s job to execute the above manoeuvre every time an application instance is to be modified. And since that happens quite often for several applications on any given day, network engineers spend a substantial part of their time performing application disables and enables. Enable/disables are needed during planned server/data center maintenance activities as well, in which case certain server pools within a data center, or sometimes data center itself, are temporarily taken down for maintenance or OS upgrades.
Another scenario that involves enables and disables at a much larger scale (though not as frequently) is Disaster Recovery (DR) simulation. This drill, where the active DC is completely shut down and brought back up after the hardware, software, and applications are thoroughly tested, requires thousands of applications and servers to be disabled/enabled. Again, traffic has to be redirected to the standby DC and carefully monitored for availability until the primary DC is made live again. The activity could go on for a month, and if network engineers are the only ones authorized to perform application swings, given their scale, they may have to spend some sleepless nights for the duration of the event.
The bottomline is that application disable/enable, or application swings as they’re more commonly known, are generally the most-frequently performed task in an enterprise. Because applications are the touchpoint when users interact with the organization, any operation on the organization’s systems entails applications to be taken care of first. Applications are the backbone of any organization, even more so when they are customer-facing. Network engineers and administrators, therefore, have to ensure that applications are constantly available to users for the duration of maintenance and update activities. This requires careful distribution, optimization, and monitoring of traffic to make sure application requests are successfully carried out.
One way to ensure constant availability is to shrink the maintenance window, something that’s possible only if application owners, network teams, and others involved are perfectly in sync, and there’s a significant amount of automation being practiced. However, this is not the case in reality. Network engineers are generally busy people working on multiple tasks at a given time, and application swings, despite being a critical exercise, is a chore because it’s time-consuming and repetitive. “Collaboration” usually means sitting down for calls with application owners and waiting for them to give the go-ahead to disable the application, have the security team validate the fix, and wait to enable applications again on their command. In case of unplanned activities, like an urgent patch roll-out for a bug fix or feature update, having to drop their current priorities abruptly to perform application swings could mess with their schedules.
Solution: Divide and Conquer. Enable DevOps to Self-service Application-centric Network Operations.
Application maintenance is the application owners’ responsibility; what if you could make them do the disable/enable part of the maintenance too by themselves and save yourself the time and effort?
You can, with AppViewX ADC+. It enables network engineers to pre-configure common application-centric network processes and share them with application owners and other DevOps Teams. You don’t have to code to create the workflows templates either; ADC+ provides a library of IT infrastructure elements that includes devices, services, and workflows of the vendors it’s integrated with, like F5 devices, ServiceNow ITSM, Ansible playbooks, etc., and basic tasks like event-based alerts, VIP creation, and so on. AppViewX can act either as Northbound or Southbound for the integrations as the process demands. You can drag and drop the elements onto the canvas and connect them in a sequence with line connectors – no need to perform individual vendor logins or API calls. You can further simplify workflow execution for application owners by creating forms to collect and validate the basic inputs required to initiate the workflow.
For the application swing, too, you can easily create the appropriate workflow using the Visual Workflow builder. The workflows can be templatized, so you can reuse the core functionality for enable/disable of all applications, and further customize the workflow for each application if required. You can then share the task snippets with the respective application owners. AppViewX integrates with popular access management solutions like LDAP, SAML, and RADIUS, and makes finding and accessing internal users a lot easier. ADC+ helps prevent unauthorized access and enforce security by providing fine-grained RBAC, where each application owner can access and manipulate only the module that they’re granted permissions for.
Each application owner gets a dashboard that displays the state, status, performance, and health of their application and the underlying infrastructure. In the event of a maintenance or upgrade activity, the application owners can perform the disable/enable manoeuvre themselves. All it takes is a few clicks, and the workflow gets executed in the background without any manual intervention whatsoever. Once they disable the application in the primary DC and enable it in the standby DC, the traffic automatically gets redirected, dropping to zero in the primary DC and simultaneously rising up in the standby DC. This event can be viewed in real-time on the application dashboard. The platform checks for the successful completion of the task by analyzing the pre- and post-configurations of the network, and alerts both the application owner and the network engineer in-case it encounters some glitch.
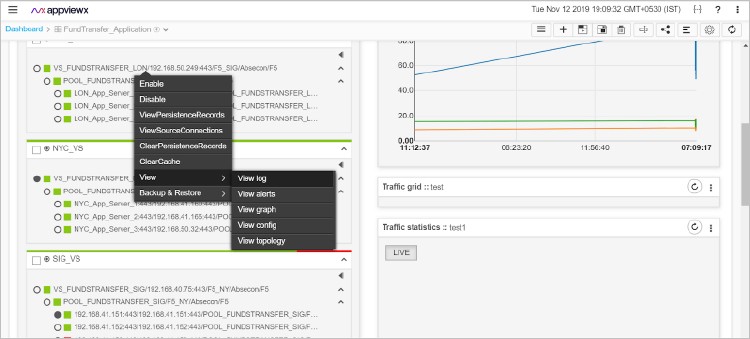
Screen showing the enable/disable widgets and application traffic graph
With self-servicing, application owners need no longer depend on network engineers every time their application needs to be worked upon. They gain significant autonomy over their applications and can subsequently be fully responsible for their upkeep. With reduced dependency and more control, application owners can implement more changes faster, thus reducing the maintenance window by an enormous amount. This, in turn, guarantees high availability and a lower incidence of errors. Network engineers, too, are freed from the numerous tickets and tedious calls that come with having to perform application swings at the behest of application owners, and can devote their energies towards solving critical network problems and bettering the network with newer technologies. It’s a win-win for all parties concerned – the application owner, the network engineer, the end-user who gets to enjoy impeccable application quality, and ultimately, the enterprise which reaps the benefits of higher employee productivity stronger networks, and happier customers.
Do automation right. Try ADC+ now for free, or schedule a demo with us.
Tags
About the Author
Nishevitha Ramamoorthy
Product Marketing Manager - AppViewX CERT+
Nishevitha is the product marketer at AppViewX. She writes, does research, and builds strategies to communicate the product's value to prospective buyers.